Was ist Technical Debt – und warum ist sie in SVN besonders gefährlich?
Technical Debt – technische Schulden – ist eine Metapher, die von Ward Cunningham geprägt wurde. Sie beschreibt die impliziten Kosten, die entstehen, wenn Entwickler bewusst oder unbewusst schnelle Lösungen wählen statt sauberer, langfristig wartbarer Implementierungen. Wie bei finanziellen Schulden fallen Zinsen an: Je länger man wartet, desto teurer wird die Rückzahlung.
In Subversion-Repositories ist dieses Problem besonders tückisch. Während Git-Nutzer mit Feature-Branches, Pull-Requests und leichtgewichtigen Forks arbeiten, folgen SVN-Projekte häufig einem zentralisierten Workflow mit langlebigen Branches und großen Monorepos. Diese Struktur hat direkte Konsequenzen für die Ansammlung technischer Schulden:
- Langlebige Branches: SVN-Branches sind vollständige Verzeichniskopien. Sie werden seltener erstellt, leben länger und divergieren stärker vom Trunk. Merges werden dadurch komplexer und fehleranfälliger – ein idealer Nährboden für technische Schulden.
- Große Monorepos: Viele SVN-Projekte beinhalten das gesamte Unternehmenscodebase in einem einzigen Repository. Abhängigkeiten zwischen Modulen sind oft nicht klar definiert, was zu versteckter Kopplung führt.
- Zentralisierter Workflow: Ohne lokale Commits fehlt die Möglichkeit, Code vor dem Hochladen zu refactoren. Entwickler committen direkt auf den Server – oft unter Zeitdruck und ohne vorherige Review.
- Fehlende Branch-Vergleiche: Anders als bei Git gibt es kein einfaches
git diff main..feature. Die Evolution von Code über Branches hinweg zu verfolgen, erfordert in SVN deutlich mehr Aufwand.
Das Ergebnis: Technische Schulden sammeln sich in SVN-Repositories oft unbemerkt an, bis sie die Entwicklungsgeschwindigkeit spürbar drosseln. Doch es gibt Wege, sie systematisch zu erkennen und zu bekämpfen.
Die Warnsignale: Wie man Technical Debt erkennt
Technische Schulden haben selten eine offensichtliche Signatur. Sie manifestieren sich in Mustern, die einzeln harmlos erscheinen, aber in ihrer Summe auf tiefgreifende Probleme hindeuten. Die folgenden Indikatoren sollten bei jedem SVN-Projekt regelmäßig geprüft werden:
Wachsende Dateigrößen
Dateien, die über die Zeit immer größer werden, sind ein klassisches Warnsignal. Eine Klasse, die vor zwei Jahren 200 Zeilen hatte und jetzt 2.000 Zeilen umfasst, hat wahrscheinlich zu viele Verantwortlichkeiten angesammelt. Das Single-Responsibility-Prinzip wurde verletzt – und jede weitere Änderung erhöht das Risiko von Seiteneffekten.
Sinkende Review-Scores
Wenn KI-gestützte Code-Reviews über die Zeit niedrigere Scores vergeben, ist das ein objektiver Indikator für nachlassende Code-Qualität. Besonders aussagekräftig sind Trends in einzelnen Kategorien wie Fehlerbehandlung, Code-Komplexität oder Namensgebung.
Hotspot-Dateien mit vielen Änderungen
Dateien, die in jeder Revision geändert werden, sind oft die kritischsten im Projekt. Sie sind entweder schlecht abstrahiert (jede neue Anforderung erfordert Änderungen), oder sie dienen als „God Objects“, die zu viele Aufgaben übernehmen. Diese Hotspots sind gleichzeitig die risikoreichsten Dateien im Repository – jede Änderung kann Seiteneffekte in vielen anderen Modulen auslösen.
⚠ Warnsignale auf einen Blick
- Dateien mit mehr als 1.000 Zeilen, die weiter wachsen
- Review-Scores, die über 3+ Commits fallen
- Dateien, die in >30% aller Commits geändert werden
- Steigende Commit-Frequenz bei gleichzeitig sinkender Feature-Velocity
- Wiederkehrende Änderungen an denselben Code-Stellen
SVN-spezifische Herausforderungen
Die Erkennung technischer Schulden in SVN stellt Entwickler vor spezifische Herausforderungen, die in Git-basierten Workflows nicht existieren:
Kein einfaches Branch-Diffing: In Git ist git log --oneline main..feature ein einzeiliger Befehl. In SVN erfordert der Vergleich zweier Branches die manuelle Konstruktion von svn diff-Befehlen mit vollständigen Repository-URLs und Revisionsnummern. Die Code-Evolution über Branches hinweg zu verfolgen, wird dadurch deutlich schwieriger.
Revisionsnummern statt Content-Hashes: SVN verwendet globale, sequentielle Revisionsnummern. Das macht es zwar einfach, die zeitliche Reihenfolge von Änderungen zu verstehen, erschwert aber die Identifikation, welche Änderungen tatsächlich zusammengehören.
Schwergewichtige History-Abfragen: Da SVN keine vollständige lokale Kopie der History vorhält, erfordern Log-Abfragen Server-Kommunikation. Die Analyse großer Revision-Bereiche kann daher zeitintensiv sein – was dazu führt, dass solche Analysen seltener durchgeführt werden.
Property-basierte Metadaten: SVN nutzt Properties (svn:mergeinfo, svn:externals) für Metadaten, die selbst eine Quelle technischer Schulden werden können. Veraltete svn:externals-Referenzen oder aufgeblähte svn:mergeinfo-Properties sind häufige Probleme in langlebigen Repositories.
SVN-Log-Analyse: Hotspots finden
Die mächtigste Waffe gegen technische Schulden in SVN ist die systematische Analyse der Commit-History. Der Befehl svn log mit der --xml-Option liefert strukturierte Daten, die sich hervorragend für automatisierte Analysen eignen.
Die wichtigsten Metriken, die sich aus SVN-Logs extrahieren lassen:
- Änderungsfrequenz pro Datei: Wie oft wurde jede Datei geändert? Dateien mit überdurchschnittlich vielen Änderungen sind potentielle Hotspots.
- Autorenkonzentration: Wird eine Datei nur von einem Entwickler gepflegt? Das deutet auf Wissens-Silos hin – eine Form organisatorischer technischer Schulden.
- Änderungskopplung: Welche Dateien werden häufig zusammen geändert? Wenn
DatabaseManager.swiftundUserInterface.swiftin 80% der Commits gemeinsam auftauchen, deutet das auf eine Verletzung der Schichtenarchitektur hin. - Commit-Größen-Trend: Werden die Commits im Laufe der Zeit größer? Steigende Commit-Größen deuten darauf hin, dass Änderungen schwieriger zu isolieren sind – ein typisches Symptom hoher Kopplung.
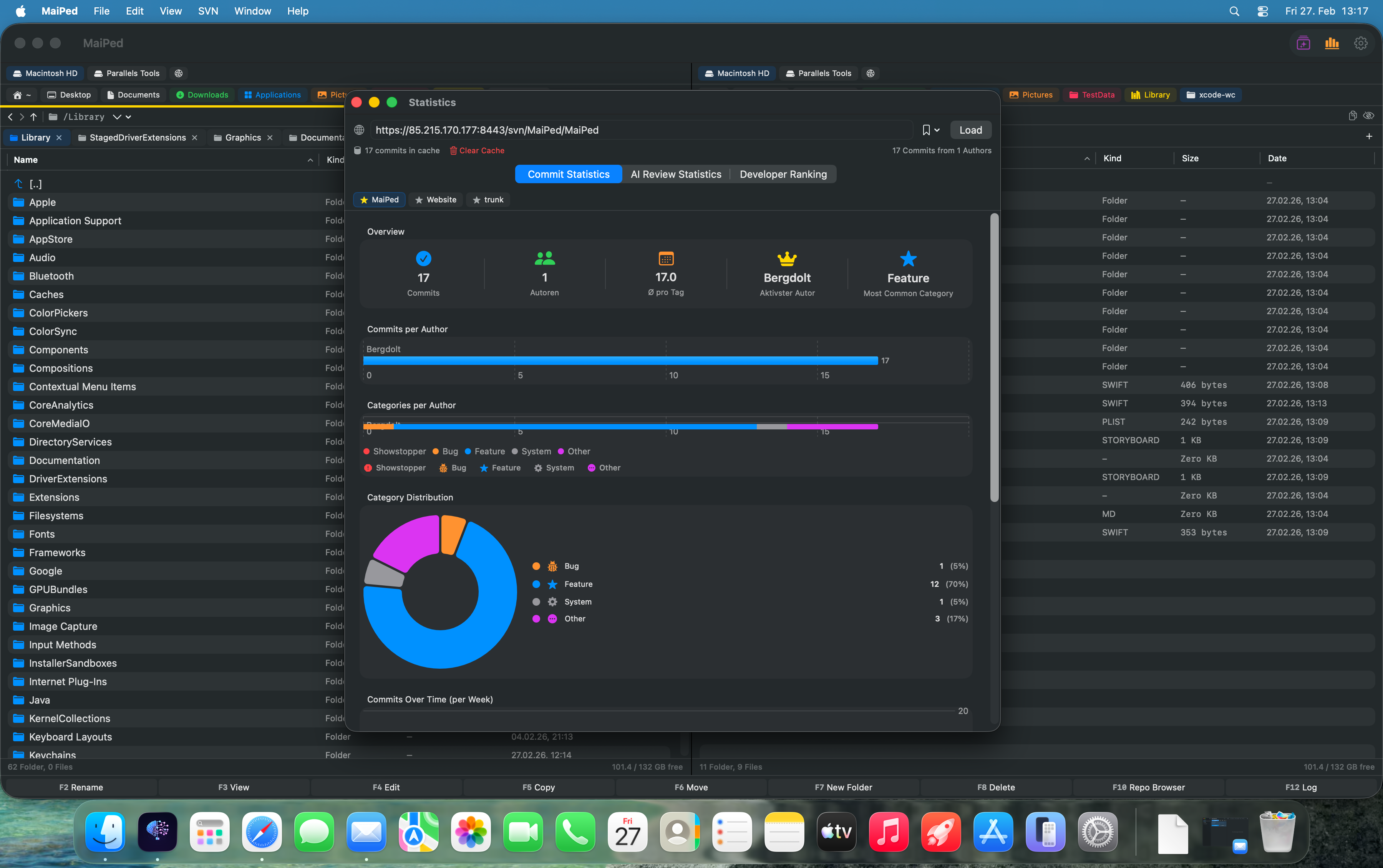
MaiPed automatisiert diese Analyse vollständig. Das Statistik-Dashboard liest die SVN-History aus und visualisiert Änderungsfrequenzen, Autorenverteilungen und Commit-Muster in interaktiven Diagrammen. Statt stundenlang Log-Dateien manuell auszuwerten, erhalten Entwickler sofort einen Überblick über die kritischsten Bereiche ihres Repositories.
KI-Code-Review: Code Smells automatisch erkennen
Während die Log-Analyse zeigt, wo Probleme liegen könnten, erklärt die KI-gestützte Code-Review, was genau das Problem ist. Moderne Sprachmodelle können Code nicht nur syntaktisch, sondern auch semantisch analysieren und dabei Muster erkennen, die menschlichen Reviewern häufig entgehen:
- Code Smells: Zu lange Methoden, zu tiefe Verschachtelungen, magische Zahlen, God Classes – die KI identifiziert klassische Entwurfsprobleme und erklärt, warum sie problematisch sind.
- Duplizierte Logik: Copy-Paste-Programmierung ist eine der häufigsten Quellen technischer Schulden. Die KI erkennt semantisch ähnliche Code-Blöcke, selbst wenn sie syntaktisch abweichen.
- Mangelhafte Fehlerbehandlung: Leere Catch-Blöcke, verschluckte Exceptions, fehlende Null-Checks – die KI bewertet die Robustheit des Error-Handlings und schlägt Verbesserungen vor.
- Inkonsistente API-Nutzung: Wenn dieselbe Bibliothek in verschiedenen Teilen des Codes auf unterschiedliche Weise verwendet wird, deutet das auf fehlende Abstraktion oder veraltete Implementierungen hin.
Der entscheidende Vorteil gegenüber statischen Analysewerkzeugen: Die KI versteht den Kontext. Sie kann erkennen, dass eine bestimmte Implementierung für einen Prototypen akzeptabel war, aber für Produktionscode überarbeitet werden sollte. Sie kann auch den Schweregrad eines Problems einschätzen und priorisierte Empfehlungen aussprechen.
MaiPeds Werkzeuge zur Erkennung technischer Schulden
MaiPed bietet drei Kernfunktionen, die zusammen ein umfassendes System zur Erkennung und Bekämpfung technischer Schulden bilden:
KI-Reviews mit Kategorie-Scores
Das Pre-Commit-Review-System analysiert jede Änderung vor dem Commit und vergibt Scores in mehreren Kategorien: Code-Qualität, Fehlerbehandlung, Sicherheit, Performance und Wartbarkeit. Jeder Score wird mit einer detaillierten Begründung versehen. Über die Zeit entsteht so ein Trend-Diagramm, das die Entwicklung der Code-Qualität pro Datei, pro Modul oder für das gesamte Repository sichtbar macht.
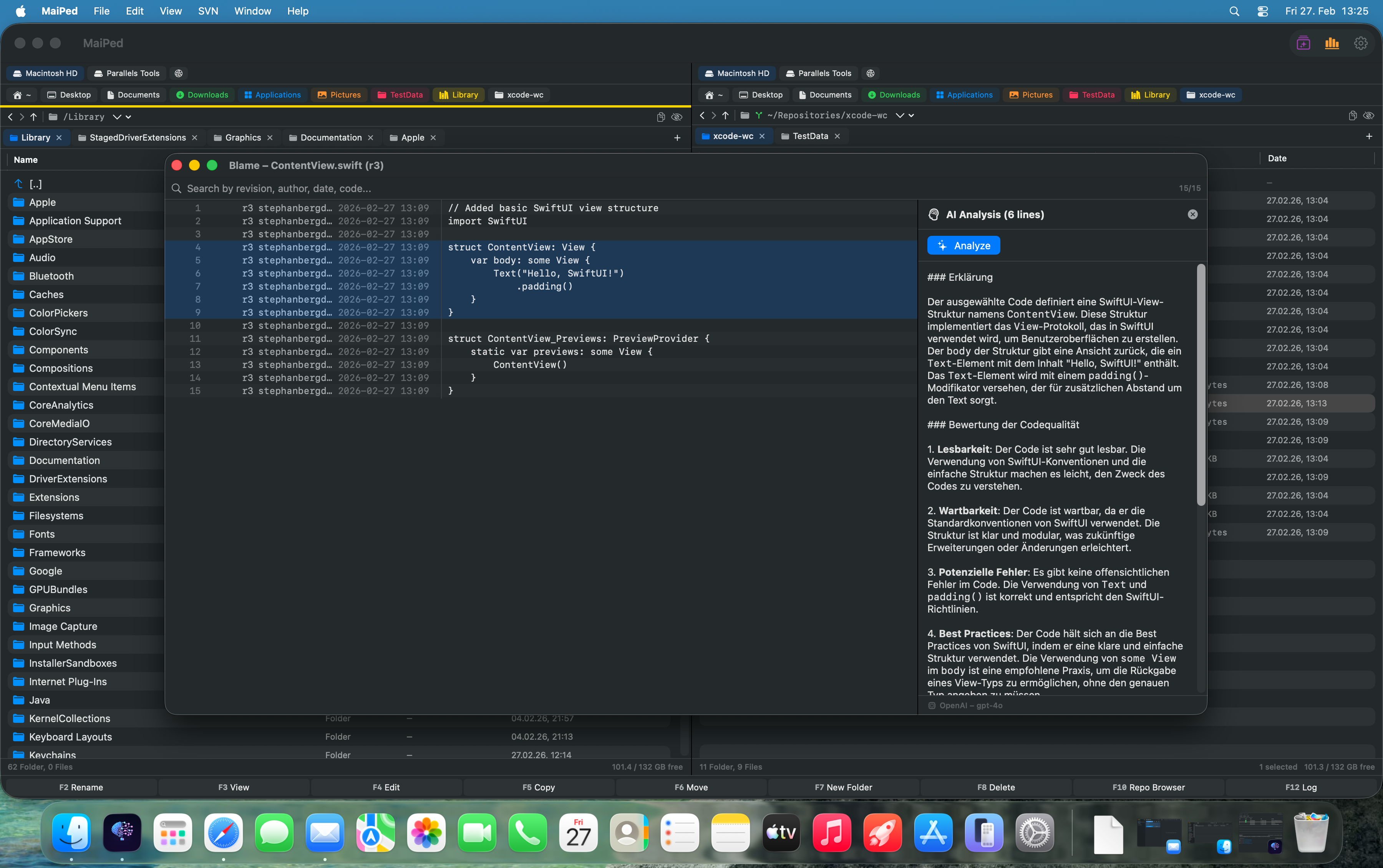
Blame-Analyse mit KI-Erklärung
Die integrierte Blame-Ansicht zeigt nicht nur, wer welche Zeile wann geändert hat, sondern ermöglicht es, die KI um eine Erklärung des historischen Kontexts zu bitten. Warum wurde diese Änderung vorgenommen? Welches Problem sollte sie lösen? Ist die Lösung noch zeitgemäß? Diese Analyse macht die Entstehungsgeschichte technischer Schulden transparent und hilft bei der Entscheidung, ob ein Refactoring lohnenswert ist.
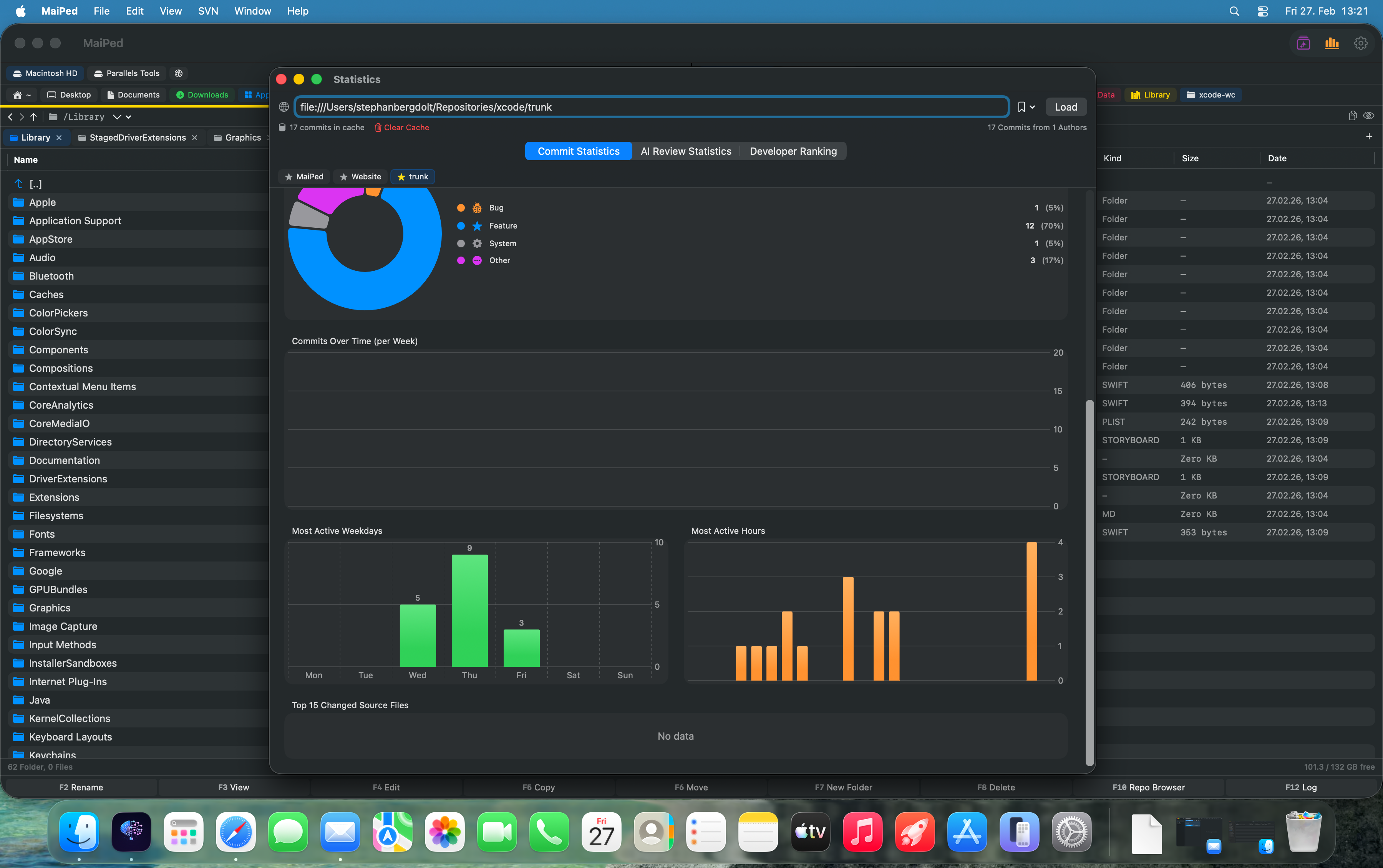
Statistik-Dashboard mit Diagrammen
Das Dashboard aggregiert Daten aus der gesamten SVN-History und präsentiert sie in übersichtlichen Diagrammen. Entwickler sehen auf einen Blick, welche Dateien die meisten Änderungen haben, wie sich Commit-Muster über die Zeit verändern und wo Wissens-Silos entstehen. Die Kombination aus quantitativer Analyse (Statistiken) und qualitativer Bewertung (KI-Reviews) liefert ein vollständiges Bild der Code-Gesundheit.
Strategien zur Schuldenreduzierung
Das Erkennen technischer Schulden ist nur der erste Schritt. Die eigentliche Herausforderung liegt in der systematischen Reduzierung. Die folgenden Strategien haben sich in SVN-Projekten bewährt:
Regelmäßige Review-Audits
Planen Sie wöchentliche oder zweiwochenliche Audits ein, bei denen das Team die KI-Review-Scores der letzten Commits analysiert. Identifizieren Sie Dateien, deren Scores konstant unter einem definierten Schwellenwert liegen, und priorisieren Sie deren Refactoring. Diese Routine stellt sicher, dass technische Schulden nicht ignoriert werden, sondern regelmäßig auf der Agenda stehen.
Score-Trends verfolgen
Ein einzelner niedriger Score ist kein Grund zur Panik. Ein fallender Trend über mehrere Commits hinweg hingegen ist ein deutliches Warnsignal. Definieren Sie klare Grenzwerte: Wenn der durchschnittliche Score eines Moduls unter 6/10 fällt, wird ein dediziertes Refactoring-Ticket erstellt. Wenn er unter 4/10 fällt, wird das Modul als kritisch markiert und erhält Priorität im nächsten Sprint.
High-Churn-Dateien fokussieren
Nicht alle technischen Schulden sind gleich dringend. Konzentrieren Sie Ihre Refactoring-Bemühungen auf Dateien mit hoher Änderungsfrequenz. Eine schlecht strukturierte Datei, die seit einem Jahr nicht angefasst wurde, ist weniger kritisch als eine, die wöchentlich geändert wird. Das Refactoring von High-Churn-Dateien hat den größten Hebeleffekt: Es verbessert die Produktivität bei jeder zukünftigen Änderung.
Neue Schulden verhindern: Pre-Commit-Reviews als Gatekeeper
Die beste Strategie gegen technische Schulden ist die Prävention. MaiPeds Pre-Commit-Review-System fungiert als automatischer Gatekeeper: Bevor Code committed wird, analysiert die KI die Änderungen und weist auf potentielle Probleme hin. Der Entwickler erhält sofortiges Feedback und kann Probleme beheben, bevor sie in die Repository-History eingehen.
Dieser Ansatz ist besonders wertvoll in SVN-Umgebungen, in denen es kein Pull-Request-System gibt. Während Git-basierte Workflows mit GitHub, GitLab oder Bitbucket automatische Reviews bei Pull-Requests ermöglichen, fehlt dieser Mechanismus in SVN. MaiPeds Pre-Commit-Reviews schließen diese Lücke und bieten SVN-Nutzern ein vergleichbares Qualitätssicherungsnetz.
Die effektivste Maßnahme gegen technische Schulden ist nicht das Refactoring bestehenden Codes – es ist die Verhinderung neuer Schulden durch konsequente, automatisierte Reviews bei jedem Commit.
Eine Roadmap zur Schuldenreduzierung erstellen
Mit den Daten, die MaiPed bereitstellt, lässt sich eine strukturierte Roadmap zur Reduzierung technischer Schulden erstellen:
- Bestandsaufnahme: Nutzen Sie das Statistik-Dashboard, um die Top-20-Hotspot-Dateien zu identifizieren. Sortieren Sie nach Änderungsfrequenz und Dateigröße.
- Bewertung: Lassen Sie die KI jede Hotspot-Datei reviewen und kategorisieren Sie die gefundenen Probleme nach Schweregrad (kritisch, hoch, mittel, niedrig).
- Priorisierung: Kombinieren Sie Änderungsfrequenz und Schweregrad zu einer Priorisierungsmatrix. Dateien mit hoher Frequenz und kritischen Problemen stehen oben auf der Liste.
- Planung: Reservieren Sie in jedem Sprint einen festen Anteil (empfohlen: 15-20%) für Refactoring-Aufgaben. Beginnen Sie mit den höchstpriorisierten Dateien.
- Messung: Verfolgen Sie die Review-Score-Trends nach jedem Refactoring-Sprint. Die Scores sollten steigen; wenn nicht, passen Sie Ihre Strategie an.
- Wiederholung: Technische Schulden sind ein kontinuierlicher Prozess. Wiederholen Sie die Bestandsaufnahme vierteliährlich, um neue Hotspots frühzeitig zu erkennen.
💡 Praxis-Tipp
- Beginnen Sie mit kleinen, isolierten Refactorings, um schnelle Erfolge zu erzielen
- Dokumentieren Sie jedes Refactoring mit einem klaren Commit-Kommentar, der das „Warum“ erklärt
- Nutzen Sie die Blame-Ansicht, um den historischen Kontext zu verstehen, bevor Sie ändern
- Setzen Sie einen Mindest-Review-Score als Team-Standard fest
- Feiern Sie Verbesserungen – steigende Scores motivieren das gesamte Team
Fazit
Technische Schulden in SVN-Repositories sind ein reales, aber beherrschbares Problem. Der Schlüssel liegt in der Kombination aus systematischer Analyse, KI-gestützter Erkennung und konsequenter Prävention. MaiPed bietet alle Werkzeuge, die SVN-Teams dafür benötigen: von der Hotspot-Analyse im Statistik-Dashboard über die kontextbewusste Blame-Analyse bis hin zu Pre-Commit-Reviews als automatische Qualitäts-Gatekeeper.
Der erste Schritt ist der wichtigste: Machen Sie technische Schulden sichtbar. Sobald Ihr Team die Daten hat, werden die richtigen Entscheidungen fast von selbst fallen.
What Is Technical Debt – and Why Is It Particularly Dangerous in SVN?
Technical debt is a metaphor coined by Ward Cunningham. It describes the implicit costs that arise when developers consciously or unconsciously choose quick solutions over clean, long-term maintainable implementations. Like financial debt, interest accrues: the longer you wait, the more expensive repayment becomes.
In Subversion repositories, this problem is particularly insidious. While Git users work with feature branches, pull requests, and lightweight forks, SVN projects often follow a centralized workflow with long-lived branches and large monorepos. This structure has direct consequences for the accumulation of technical debt:
- Long-lived branches: SVN branches are complete directory copies. They are created less frequently, live longer, and diverge more significantly from the trunk. Merges become more complex and error-prone – an ideal breeding ground for technical debt.
- Large monorepos: Many SVN projects contain the entire company codebase in a single repository. Dependencies between modules are often poorly defined, leading to hidden coupling.
- Centralized workflow: Without local commits, there is no opportunity to refactor code before pushing. Developers commit directly to the server – often under time pressure and without prior review.
- No easy branch diffing: Unlike Git, there is no simple
git diff main..feature. Tracking code evolution across branches requires significantly more effort in SVN.
The result: technical debt accumulates in SVN repositories often unnoticed until it measurably throttles development velocity. But there are ways to systematically detect and combat it.
The Warning Signs: How to Spot Technical Debt
Technical debt rarely has an obvious signature. It manifests in patterns that appear harmless individually but in aggregate point to deep-rooted problems. The following indicators should be checked regularly in every SVN project:
Growing File Sizes
Files that grow larger over time are a classic warning sign. A class that was 200 lines two years ago and now spans 2,000 lines has likely accumulated too many responsibilities. The Single Responsibility Principle has been violated – and every further change increases the risk of side effects.
Decreasing Review Scores
When AI-powered code reviews assign lower scores over time, this is an objective indicator of declining code quality. Trends in individual categories such as error handling, code complexity, or naming conventions are particularly revealing.
Hotspot Files with Many Changes
Files that are modified in every revision are often the most critical in the project. They are either poorly abstracted (every new requirement demands changes) or they serve as God Objects that take on too many responsibilities. These hotspots are simultaneously the riskiest files in the repository – any change can trigger side effects in many other modules.
⚠ Warning Signs at a Glance
- Files exceeding 1,000 lines that continue to grow
- Review scores dropping over 3+ consecutive commits
- Files modified in >30% of all commits
- Increasing commit frequency while feature velocity decreases
- Recurring changes to the same code locations
SVN-Specific Challenges
Detecting technical debt in SVN presents developers with specific challenges that do not exist in Git-based workflows:
No easy branch diffing: In Git, git log --oneline main..feature is a one-line command. In SVN, comparing two branches requires manually constructing svn diff commands with full repository URLs and revision numbers. Tracking code evolution across branches becomes significantly harder.
Revision numbers instead of content hashes: SVN uses global, sequential revision numbers. While this makes it easy to understand the chronological order of changes, it makes it harder to identify which changes actually belong together.
Heavyweight history queries: Since SVN does not maintain a complete local copy of the history, log queries require server communication. Analyzing large revision ranges can therefore be time-consuming – which leads to such analyses being performed less frequently.
Property-based metadata: SVN uses properties (svn:mergeinfo, svn:externals) for metadata that can themselves become a source of technical debt. Outdated svn:externals references or bloated svn:mergeinfo properties are common problems in long-lived repositories.
SVN Log Analysis: Finding Hotspots
The most powerful weapon against technical debt in SVN is systematic analysis of the commit history. The svn log command with the --xml option provides structured data that is excellent for automated analysis.
The key metrics that can be extracted from SVN logs:
- Change frequency per file: How often was each file modified? Files with above-average change counts are potential hotspots.
- Author concentration: Is a file maintained by only one developer? This indicates knowledge silos – a form of organizational technical debt.
- Change coupling: Which files are frequently changed together? If
DatabaseManager.swiftandUserInterface.swiftappear together in 80% of commits, this suggests a violation of layered architecture. - Commit size trend: Are commits getting larger over time? Increasing commit sizes indicate that changes are harder to isolate – a typical symptom of high coupling.
MaiPed automates this analysis completely. The statistics dashboard reads the SVN history and visualizes change frequencies, author distributions, and commit patterns in interactive charts. Instead of spending hours manually parsing log files, developers get an immediate overview of the most critical areas of their repository.
AI Code Review: Automatically Detecting Code Smells
While log analysis shows where problems might lie, AI-powered code review explains what exactly the problem is. Modern language models can analyze code not just syntactically but also semantically, detecting patterns that human reviewers often miss:
- Code smells: Methods that are too long, nesting that is too deep, magic numbers, God Classes – the AI identifies classic design problems and explains why they are problematic.
- Duplicated logic: Copy-paste programming is one of the most common sources of technical debt. The AI recognizes semantically similar code blocks, even when they differ syntactically.
- Poor error handling: Empty catch blocks, swallowed exceptions, missing null checks – the AI evaluates the robustness of error handling and suggests improvements.
- Inconsistent API usage: When the same library is used in different ways across different parts of the code, this indicates missing abstraction or outdated implementations.
The decisive advantage over static analysis tools: the AI understands context. It can recognize that a particular implementation was acceptable for a prototype but should be reworked for production code. It can also assess the severity of a problem and provide prioritized recommendations.
MaiPed's Tools for Detecting Technical Debt
MaiPed offers three core capabilities that together form a comprehensive system for detecting and combating technical debt:
AI Reviews with Category Scores
The pre-commit review system analyzes every change before the commit and assigns scores across multiple categories: code quality, error handling, security, performance, and maintainability. Each score comes with a detailed explanation. Over time, this creates a trend chart that makes the evolution of code quality visible per file, per module, or for the entire repository.
Blame Analysis with AI Explanation
The integrated blame view shows not only who changed which line and when, but also allows you to ask the AI for an explanation of the historical context. Why was this change made? What problem was it supposed to solve? Is the solution still appropriate? This analysis makes the origin story of technical debt transparent and helps in deciding whether refactoring is worthwhile.
Statistics Dashboard with Charts
The dashboard aggregates data from the entire SVN history and presents it in clear charts. Developers can see at a glance which files have the most changes, how commit patterns evolve over time, and where knowledge silos are forming. The combination of quantitative analysis (statistics) and qualitative assessment (AI reviews) delivers a complete picture of code health.
Strategies for Debt Reduction
Detecting technical debt is only the first step. The real challenge lies in systematic reduction. The following strategies have proven effective in SVN projects:
Regular Review Audits
Schedule weekly or biweekly audits where the team analyzes AI review scores from recent commits. Identify files whose scores consistently fall below a defined threshold and prioritize their refactoring. This routine ensures that technical debt is not ignored but regularly placed on the agenda.
Track Score Trends
A single low score is no reason for alarm. A declining trend over multiple commits, however, is a clear warning signal. Define clear thresholds: if the average score of a module drops below 6/10, a dedicated refactoring ticket is created. If it drops below 4/10, the module is flagged as critical and receives priority in the next sprint.
Focus on High-Churn Files
Not all technical debt is equally urgent. Concentrate your refactoring efforts on files with high change frequency. A poorly structured file that has not been touched in a year is less critical than one that is modified weekly. Refactoring high-churn files has the greatest leverage effect: it improves productivity with every future change.
Preventing New Debt: Pre-Commit Reviews as Gatekeepers
The best strategy against technical debt is prevention. MaiPed's pre-commit review system acts as an automatic gatekeeper: before code is committed, the AI analyzes the changes and flags potential problems. The developer receives immediate feedback and can fix issues before they enter the repository history.
This approach is particularly valuable in SVN environments where there is no pull request system. While Git-based workflows with GitHub, GitLab, or Bitbucket enable automatic reviews on pull requests, this mechanism is absent in SVN. MaiPed's pre-commit reviews bridge this gap, providing SVN users with a comparable quality assurance safety net.
The most effective measure against technical debt is not refactoring existing code – it is preventing new debt through consistent, automated reviews with every commit.
Building a Debt Reduction Roadmap
With the data MaiPed provides, you can create a structured roadmap for reducing technical debt:
- Inventory: Use the statistics dashboard to identify the top 20 hotspot files. Sort by change frequency and file size.
- Assessment: Have the AI review each hotspot file and categorize the problems found by severity (critical, high, medium, low).
- Prioritization: Combine change frequency and severity into a prioritization matrix. Files with high frequency and critical problems go to the top of the list.
- Planning: Reserve a fixed portion of each sprint (recommended: 15-20%) for refactoring tasks. Start with the highest-priority files.
- Measurement: Track review score trends after each refactoring sprint. Scores should rise; if they do not, adjust your strategy.
- Iteration: Technical debt is a continuous process. Repeat the inventory quarterly to catch new hotspots early.
💡 Practical Tips
- Start with small, isolated refactorings to achieve quick wins
- Document every refactoring with a clear commit message that explains the “why”
- Use the blame view to understand historical context before making changes
- Set a minimum review score as a team standard
- Celebrate improvements – rising scores motivate the entire team
Conclusion
Technical debt in SVN repositories is a real but manageable problem. The key lies in the combination of systematic analysis, AI-powered detection, and consistent prevention. MaiPed provides all the tools SVN teams need: from hotspot analysis in the statistics dashboard through context-aware blame analysis to pre-commit reviews as automatic quality gatekeepers.
The first step is the most important: make technical debt visible. Once your team has the data, the right decisions will almost make themselves.