Warum Commit-Qualität wichtig ist
In der Softwareentwicklung wird viel über Clean Code, Test-Driven Development und agile Methoden gesprochen. Doch ein Aspekt wird dabei häufig übersehen: die Qualität einzelner Commits. Jeder Commit ist mehr als eine Sammlung von Code-Änderungen – er ist eine dokumentierte Entscheidung, die direkte Auswirkungen auf drei zentrale Bereiche hat.
Technische Schulden (Technical Debt): Commits mit geringer Qualität – fehlende Fehlerbehandlung, inkonsistente Namensgebung, hartcodierte Werte – häufen sich über die Zeit zu einer erdrückenden Last an. Was heute als schnelle Lösung erscheint, wird morgen zum Stolperstein. Studien zeigen, dass Entwicklerteams durchschnittlich 33% ihrer Zeit damit verbringen, technische Schulden zu beheben, statt neue Features zu entwickeln. Jeder einzelne Commit, der Schulden aufbaut, multipliziert diesen Effekt.
Team-Velocity: Die Geschwindigkeit, mit der ein Team neue Funktionen ausliefern kann, hängt direkt von der Qualität der bestehenden Codebasis ab. Wenn jeder Commit sauber, gut dokumentiert und durchdacht ist, können andere Teammitglieder den Code schneller verstehen, erweitern und debuggen. Schlechte Commits erzeugen Reibung: Entwickler müssen mehr Zeit mit dem Verstehen von Code verbringen, Bugs treten häufiger auf, und Regressionen werden wahrscheinlicher.
Code-Wartbarkeit: Software lebt länger als die meisten Entwickler in einem Projekt bleiben. Ein Commit, der heute geschrieben wird, wird möglicherweise in zwei Jahren von einem völlig anderen Entwickler gelesen und geändert. Commit-Qualität bestimmt, ob dieser zukünftige Entwickler produktiv arbeiten kann oder frustriert aufgibt. Gute Commits erzählen eine Geschichte: Sie erklären das Warum, nicht nur das Was.
Die wahren Kosten schlechter Commits werden nie sofort sichtbar. Sie manifestieren sich erst Wochen oder Monate später – als Bug, als Performance-Problem oder als Onboarding-Hürde für neue Teammitglieder.
Traditionelle Ansätze zur Qualitätssicherung
Teams haben über die Jahre verschiedene Methoden entwickelt, um die Qualität von Code-Änderungen sicherzustellen. Jede hat ihre Stärken und Schwächen.
Manuelle Code Reviews
Der klassische Ansatz: Ein erfahrener Entwickler liest den geänderten Code Zeile für Zeile und gibt Feedback. Manuelle Reviews sind wertvoll, weil sie Kontext berücksichtigen, den kein automatisiertes Tool erfassen kann – Architekturentscheidungen, Business-Logik, Teamkonventionen. Der Nachteil ist offensichtlich: sie skalieren nicht. Ein Senior-Entwickler kann pro Tag nur eine begrenzte Anzahl Reviews durchführen. Außerdem sind menschliche Reviews subjektiv. Was Reviewer A für akzeptabel hält, wird von Reviewer B möglicherweise abgelehnt. Die Qualität des Reviews hängt stark von der Tagesform, dem Zeitdruck und der Erfahrung des Reviewers ab.
Pull Request Reviews
In der Git-Welt haben sich Pull Requests (oder Merge Requests) als Standard-Workflow etabliert. Der Entwickler erstellt einen Branch, macht seine Änderungen, und reicht einen PR zur Überprüfung ein. Erst nach Genehmigung wird der Code in den Hauptbranch gemergt. Dieses System bietet eine strukturierte Gate-Funktion: kein ungeprüfter Code gelangt in die Produktion. Plattformen wie GitHub und GitLab bieten dazu umfangreiche Werkzeuge – Inline-Kommentare, Status-Checks, automatische Reviewer-Zuordnung.
Pair Programming
Beim Pair Programming sitzen zwei Entwickler gemeinsam am Code. Der „Driver“ schreibt, der „Navigator“ denkt mit, hinterfragt Entscheidungen und erkennt Fehler in Echtzeit. Diese Methode produziert oft hochwertigen Code, weil jede Zeile implizit von zwei Personen geprüft wird. Der Nachteil sind die hohen Kosten: Zwei Entwickler arbeiten an einer Aufgabe. Außerdem ist Pair Programming bei verteilten Teams oder asynchroner Arbeit schwer umsetzbar.
Alle diese Ansätze teilen ein fundamentales Problem: sie messen Qualität nicht quantitativ. Ein Review endet mit „approved“ oder „changes requested“ – aber es gibt keine Zahl, keinen Score, kein Tracking über die Zeit. Man kann nicht sagen: „Unsere durchschnittliche Commit-Qualität ist in Q3 um 12% gestiegen.“
Metriken, die zählen
Um Commit-Qualität messbar zu machen, brauchen wir konkrete, quantifizierbare Metriken. Hier sind die wichtigsten.
Diff-Größe: Die Anzahl geänderter Zeilen pro Commit ist einer der zuverlässigsten Indikatoren für Commit-Qualität. Kleine, fokussierte Commits (unter 400 Zeilen) sind leichter zu reviewen, einfacher rückgängig zu machen und erzeugen weniger Merge-Konflikte. Große Commits (1000+ Zeilen) deuten oft auf mangelnde Planung hin – der Entwickler hat zu viele Aufgaben in einem einzigen Commit vermischt. Die Wahrscheinlichkeit, dass ein Reviewer einen Fehler in einem 2000-Zeilen-Diff übersieht, ist drastisch höher als bei einem 200-Zeilen-Diff.
Test-Coverage-Änderungen: Ein guter Commit fügt nicht nur neuen Code hinzu, sondern auch die entsprechenden Tests. Die entscheidende Frage ist nicht „Wie hoch ist die Gesamt-Coverage?“, sondern „Hat dieser Commit die Coverage verbessert, verschlechtert oder beibehalten?“ Commits, die neuen Code ohne Tests einführen, senken die relative Coverage und erhöhen das Regressionsrisiko.
Zyklomatische Komplexität: Diese Metrik misst die Anzahl unabhängiger Pfade durch eine Funktion. Eine Funktion mit einem einzigen if-Statement hat eine Komplexität von 2 (zwei Pfade). Jede weitere Bedingung, Schleife oder Switch-Case erhöht die Komplexität. Commits, die die zyklomatische Komplexität von Funktionen über 10 treiben, signalisieren, dass die Funktion aufgeteilt werden sollte. Hohe Komplexität korreliert direkt mit der Fehlerhäufigkeit.
Dokumentationsanteil: Das Verhältnis von Kommentaren und Dokumentation zum Code verrät viel über die Wartbarkeit. Dabei geht es nicht um banale Zeilenkommentare („Inkrement zähler“), sondern um aussagekräftige Erklärungen, warum eine Entscheidung getroffen wurde, welche Annahmen gelten und welche Edge-Cases berücksichtigt wurden. Ein Commit ohne jegliche Dokumentation in einem komplexen Bereich ist ein Warnsignal.
Das SVN-Problem: Kein eingebauter Pull-Request-Workflow
Während Git-basierte Plattformen wie GitHub, GitLab und Bitbucket umfangreiche Review-Werkzeuge bieten, stehen SVN-Teams vor einer grundlegenden Herausforderung: SVN hat keinen nativen Pull-Request-Mechanismus.
In SVN committen Entwickler direkt auf den trunk oder einen Branch. Es gibt keinen zwischengeschalteten Review-Schritt, keinen „Request for Merge“, keine automatische Reviewer-Zuweisung. Der Commit ist sofort Teil des Repositorys. Dieses Modell hat seinen Ursprung in einer Zeit, in der Teams kleiner waren und Vertrauen die primäre Qualitätssicherung darstellte.
In modernen Teams, besonders in regulierten Branchen (Medizintechnik, Automobilindustrie, Finanzwesen), ist dieses Modell problematisch. Unternehmen, die SVN aus historischen Gründen verwenden – bestehende Infrastruktur, Compliance-Anforderungen, große Binärdateien – haben oft keine Werkzeuge für systematische Pre-Commit-Reviews.
Einige Teams bauen Workarounds: Pre-Commit-Hooks, die statische Analyse erzwingen, oder manuelle Review-Prozesse per E-Mail oder Ticket-System. Aber diese Lösungen sind fragmentiert, schwer wartbar und liefern keine Trend-Daten über die Zeit. Genau hier eröffnet die Integration von KI-gestützten Reviews direkt im SVN-Client völlig neue Möglichkeiten.
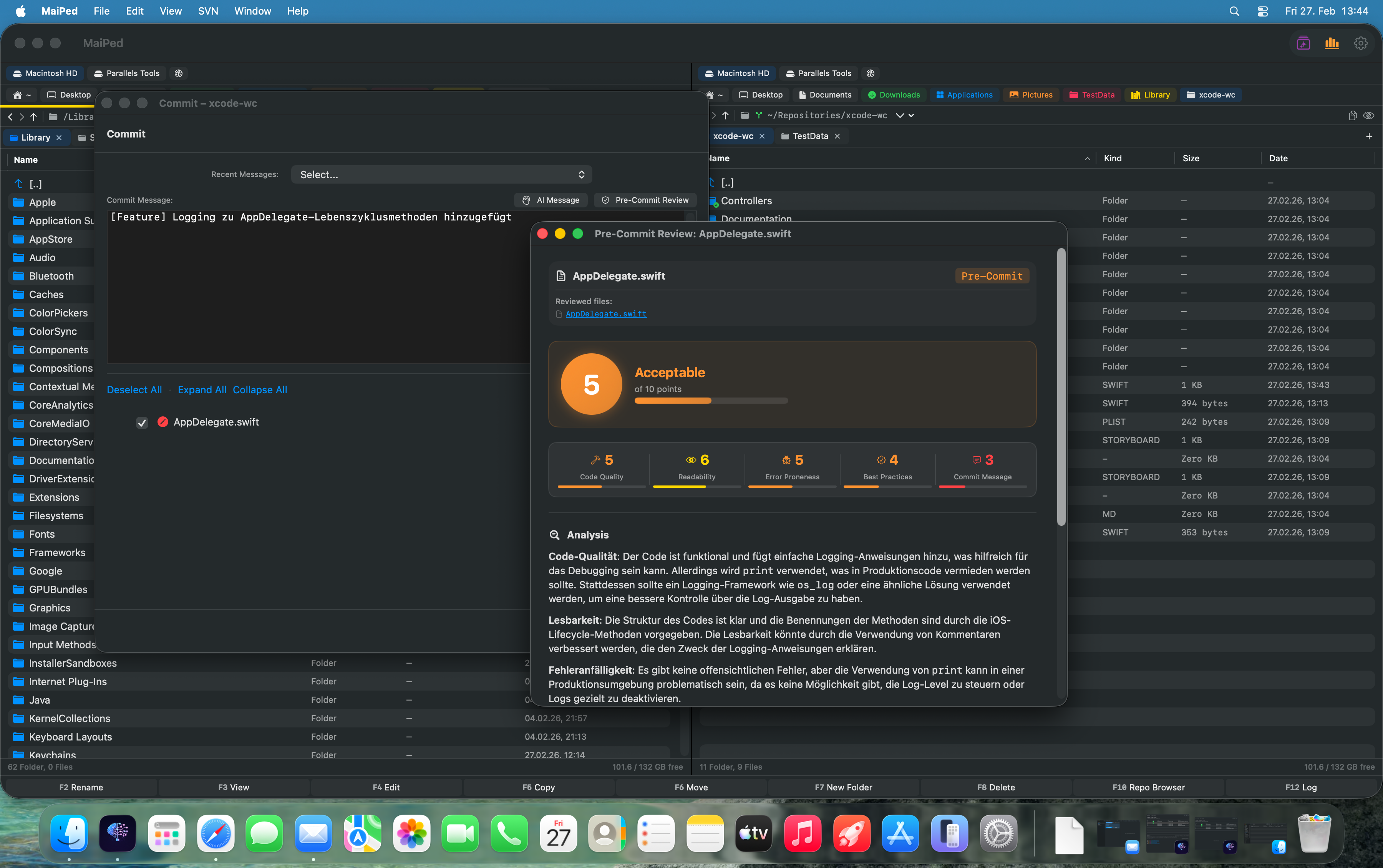
Wie KI Commits objektiv bewerten kann
KI-basierte Code-Reviews lösen mehrere fundamentale Probleme traditioneller Ansätze gleichzeitig. Ein KI-Modell bewertet jeden Commit nach denselben Kriterien – unabhängig von Tagesform, persönlichen Vorlieben oder Zeitdruck. Diese Konsistenz ist der größte Vorteil gegenüber menschlichen Reviews.
Ein KI-Review kann den Diff eines Commits analysieren und bewerten in Kategorien wie:
- Code-Qualität – Ist der Code sauber strukturiert? Folgt er etablierten Patterns? Gibt es unnötige Komplexität?
- Fehlerbehandlung – Werden Fehlerbedingungen berücksichtigt? Gibt es Try/Catch-Blöcke wo nötig? Werden Edge-Cases behandelt?
- Performance – Gibt es ineffiziente Algorithmen, unnötige Berechnungen oder potenzielle Memory-Leaks?
- Dokumentation – Sind Kommentare vorhanden und aussagekräftig? Ist die Commit-Nachricht beschreibend?
Der entscheidende Unterschied: Jede Kategorie erhält einen numerischen Score (z.B. 1–10). Dadurch wird Qualität von einer subjektiven Einschätzung zu einem messbaren Wert. Man kann diese Scores über die Zeit tracken, Durchschnitte bilden, Trends erkennen und Verbesserungen quantifizieren.
Wichtig ist, dass KI-Reviews menschliche Reviews nicht ersetzen, sondern ergänzen. Die KI funkt als konsistente Erstprüfung – sie fängt offensichtliche Probleme ab, bevor ein menschlicher Reviewer seine wertvolle Zeit investiert. Dadurch können sich menschliche Reviewer auf die wirklich wichtigen Aspekte konzentrieren: Architekturentscheidungen, Business-Logik und strategische Implikationen.
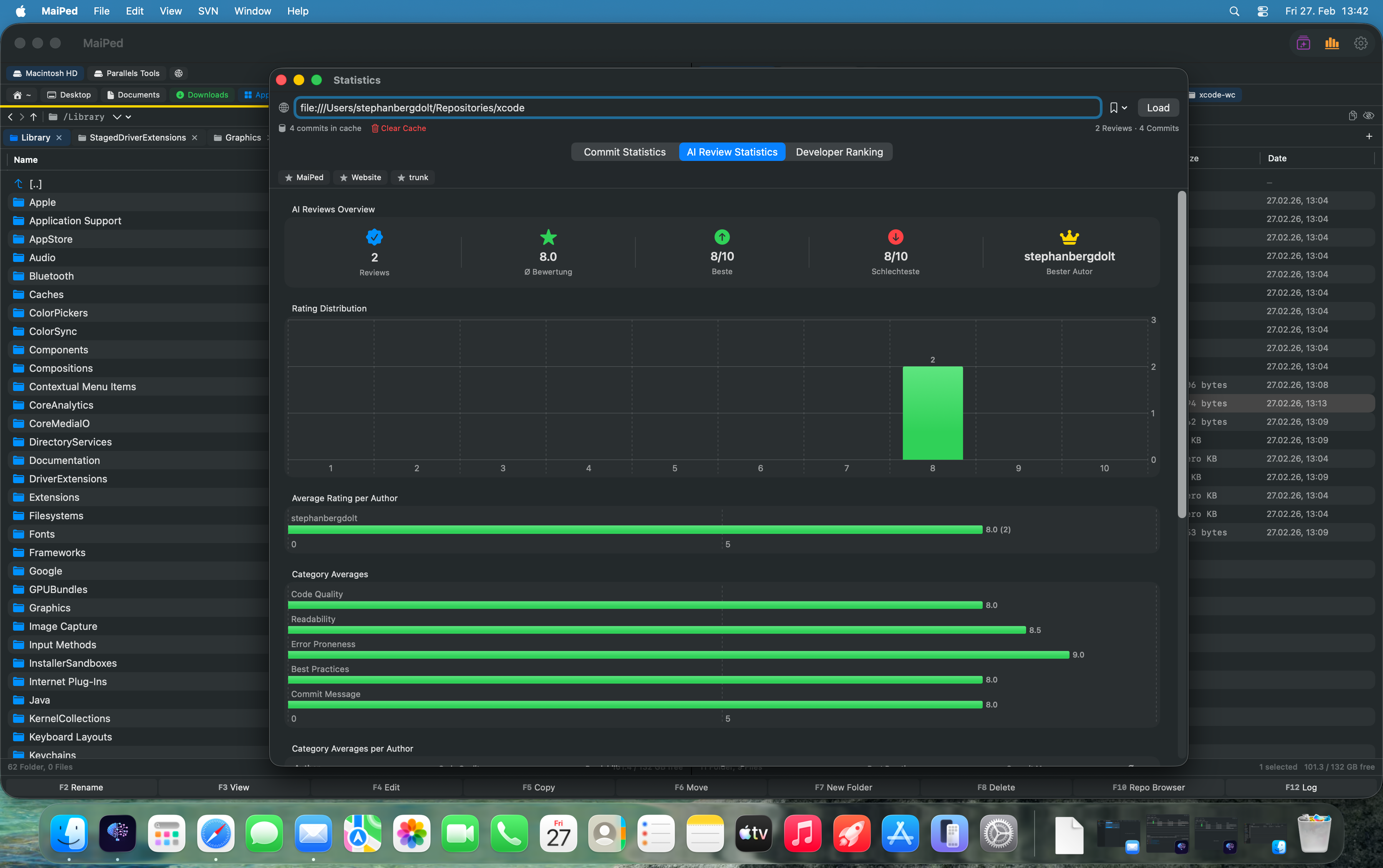
MaiPeds Ansatz: Kategorie-Scores und Trendanalyse
MaiPed integriert KI-gestützte Code-Reviews direkt in den SVN-Commit-Workflow. Bevor ein Commit ausgeführt wird, analysiert die KI die Änderungen und bewertet sie in mehreren Kategorien mit Scores von 1 bis 10.
Neben Einzel-Reviews bietet MaiPed Batch-Reviews, bei denen mehrere geänderte Dateien in einem Durchgang analysiert werden. Das ist besonders nützlich, wenn man einen größeren Feature-Branch fertiggestellt hat und vor dem Commit einen Gesamtüberblick über die Qualität aller Änderungen haben möchte.
Alle Review-Ergebnisse werden in MaiPeds lokaler SQLite-Datenbank gespeichert und in der Statistik-Ansicht als interaktive Charts visualisiert. Dort sieht man auf einen Blick, wie sich die Review-Scores über Wochen und Monate entwickeln, welche Kategorien sich verbessern und wo Rückschritte stattfinden. Diese Daten geben dem gesamten Team eine gemeinsame Grundlage für Qualitätsdiskussionen – basierend auf Fakten statt auf Bauchgefühl.
Ein weiterer Vorteil: Die KI-Anbieter sind frei wählbar. Teams können OpenAI, Anthropic oder Mistral verwenden – oder für maximale Privatsphäre lokale Modelle wie Ollama und LM Studio einsetzen. Dabei verlässt kein einziges Byte den Rechner.
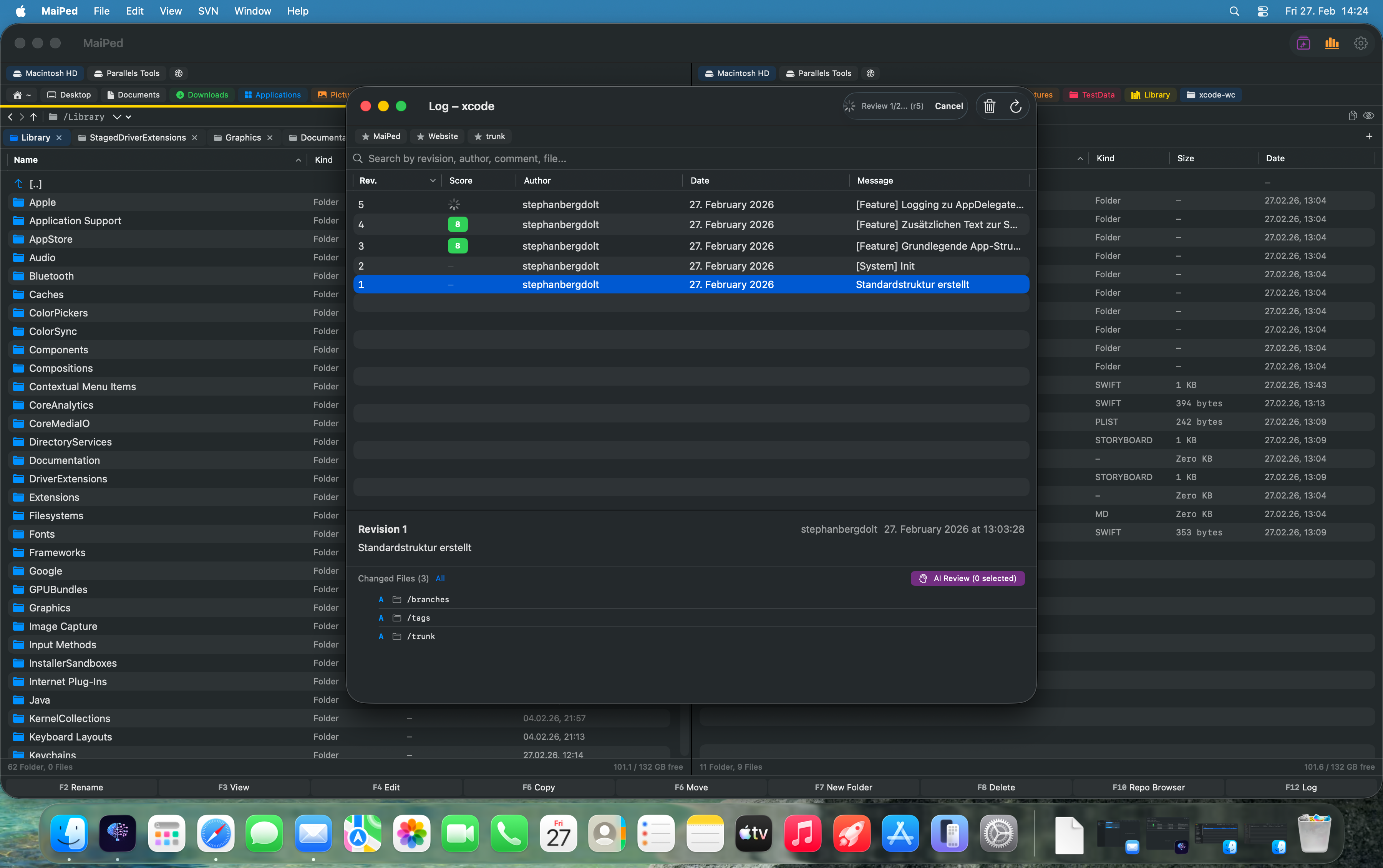
Muster erkennen mit Review-Scores
Der größte Wert numerischer Review-Scores liegt nicht im einzelnen Ergebnis, sondern in den Mustern, die sich über die Zeit abzeichnen. Wenn man Scores über Wochen und Monate trackt, werden Trends sichtbar, die bei einzelnen Reviews unsichtbar bleiben.
Sinkende Qualität erkennen: Wenn die Durchschnittswerte für Code-Qualität über drei Wochen kontinuierlich fallen, ist das ein klares Signal. Vielleicht steht eine Deadline bevor und das Team opfert Qualität für Geschwindigkeit. Vielleicht hat ein neues Teammitglied die Konventionen noch nicht verinnerlicht. Ohne Daten würde dieses Problem erst später durch Bugs oder Customer-Tickets sichtbar.
Spezifische Problemfelder identifizieren: Wenn die Fehlerbehandlungs-Scores durchgängig niedrig sind (z.B. 5–6), während Code-Qualität und Performance bei 8–9 liegen, weiß das Team genau, wo es ansetzen muss. Man kann gezielte Workshops organisieren, Coding-Guidelines ergänzen oder Templates für Error-Handling bereitstellen.
Verbesserungen quantifizieren: Nach einem Team-Workshop zum Thema Dokumentation sollten die Dokumentations-Scores in den folgenden Wochen steigen. Wenn sie es nicht tun, war der Workshop nicht effektiv genug. Ohne messbare Daten wäre diese Erkenntnis rein spekulativ.
Individuelle Entwicklung: Commits-pro-Autor-Statistiken kombiniert mit durchschnittlichen Review-Scores zeigen die Entwicklung einzelner Teammitglieder. Ein Junior-Entwickler, dessen Scores über Monate stetig steigen, macht erkennbare Fortschritte. Diese Daten können in Performance-Gesprächen als objektive Grundlage dienen – positiv und konstruktiv.
Eine Qualitätskultur aufbauen
Das mächtigste Werkzeug für Commit-Qualität ist nicht Technologie, sondern Kultur. Pre-Commit Reviews – ob von einer KI oder einem Kollegen – müssen als Sicherheitsnetz verstanden werden, nicht als Instrument der Überwachung oder Schuldzuweisung.
Wenn ein Entwickler einen Commit mit niedrigen Scores sieht, sollte die erste Reaktion nicht Scham sein, sondern Neugier: Was kann ich verbessern? Was habe ich übersehen? Der Score ist Feedback, kein Urteil. Teams, die diese Haltung verinnerlicht haben, zeigen nachweislich höhere Commit-Qualität und gleichzeitig höhere Mitarbeiterzufriedenheit.
Entscheidend ist die Art, wie Scores kommuniziert werden. Sie sollten nie in öffentlichen Rankings oder Leaderboards präsentiert werden, die Einzelpersonen bloßstellen könnten. Stattdessen eignen sich aggregierte Team-Metriken: „Unsere durchschnittliche Fehlerbehandlungs-Score ist von 6.8 auf 7.9 gestiegen.“ Das feiert den Teamerfolg, ohne Individuen unter Druck zu setzen.
Pre-Commit Reviews funktionieren am besten als optionale, informative Schicht. Der Entwickler sieht die Scores vor dem Commit und kann entscheiden, ob er Änderungen vornimmt oder den Commit trotzdem ausführt. Es gibt kein automatisches Blockieren. Diese Freiwilligkeit ist psychologisch entscheidend: Menschen akzeptieren Feedback besser, wenn sie die Kontrolle über die Reaktion behalten.
Praktische Tipps für SVN-Teams
Für Teams, die SVN verwenden und ihre Commit-Qualität verbessern möchten, hier konkrete, sofort umsetzbare Empfehlungen:
- Kleine Commits: Beschränke jeden Commit auf eine logische Änderung. „Feature X implementiert“ und „Refactoring von Modul Y“ gehören in separate Commits, auch wenn sie zeitgleich entstanden sind.
- Commit-Nachrichten mit Kontext: Schreibe nicht nur was geändert wurde, sondern warum. „Fixed bug in parser“ wird zu „Fixed null pointer in XML parser when processing empty attributes (Ticket #4521)“.
- Pre-Commit Reviews aktivieren: Nutze ein Tool wie MaiPed, das KI-Reviews direkt vor dem Commit anbietet. Die zusätzlichen 10–15 Sekunden Wartezeit sparen Stunden an späterem Debugging.
- Kategorie-Scores tracken: Erfasse die Bewertungen über die Zeit und prüfe monatlich die Trends. Sinkende Scores in einer Kategorie sind ein Frühwarnsignal.
- Batch-Reviews vor größeren Releases: Vor einem Release alle geänderten Dateien einem Batch-Review unterziehen. Das fängt Probleme ab, die bei einzelnen Commits nicht sichtbar waren.
- Team-Retrospektiven mit Daten: Bringe die Review-Score-Trends in Sprint-Retrospektiven ein. Diskutiere Muster gemeinsam und leite konkrete Maßnahmen ab.
- Dokumentation als Gewohnheit: Erstelle für das Team eine Checklist: Jeder Commit sollte mindestens eine Zeile Kommentar pro neuer Funktion und eine beschreibende Commit-Nachricht enthalten.
- Lokale KI für Privatsphäre: In regulierten Branchen oder bei sensiblem Code: Verwende lokale Modelle (Ollama, LM Studio) für die Reviews. Der Code verlässt den Rechner nie.
Commit-Qualität messbar machen
MaiPed bringt KI-gestützte Code-Reviews mit Kategorie-Scores, Batch-Reviews und Trend-Tracking direkt in deinen SVN-Workflow – nativ für macOS.
Why Commit Quality Matters
In software development, there is extensive discussion about clean code, test-driven development, and agile methodologies. Yet one aspect is frequently overlooked: the quality of individual commits. Every commit is more than a collection of code changes – it is a documented decision that has direct consequences in three critical areas.
Technical Debt: Low-quality commits – missing error handling, inconsistent naming, hardcoded values – accumulate over time into an overwhelming burden. What appears today as a quick fix becomes tomorrow's stumbling block. Studies show that development teams spend an average of 33% of their time addressing technical debt instead of building new features. Every single commit that adds debt multiplies this effect.
Team Velocity: The speed at which a team can deliver new features directly depends on the quality of the existing codebase. When every commit is clean, well-documented, and thoughtfully constructed, other team members can understand, extend, and debug the code more quickly. Poor commits create friction: developers spend more time comprehending code, bugs appear more frequently, and regressions become more likely.
Code Maintainability: Software outlives most developers' tenure on a project. A commit written today may be read and modified by a completely different developer two years from now. Commit quality determines whether that future developer can work productively or gives up in frustration. Good commits tell a story: they explain the why, not just the what.
The true cost of poor commits is never immediately visible. It manifests only weeks or months later – as a bug, a performance issue, or an onboarding hurdle for new team members.
Traditional Approaches to Quality Assurance
Teams have developed various methods over the years to ensure the quality of code changes. Each has its strengths and weaknesses.
Manual Code Reviews
The classic approach: an experienced developer reads the changed code line by line and provides feedback. Manual reviews are valuable because they account for context that no automated tool can capture – architectural decisions, business logic, team conventions. The downside is obvious: they do not scale. A senior developer can only perform a limited number of reviews per day. Furthermore, human reviews are subjective. What Reviewer A finds acceptable may be rejected by Reviewer B. The quality of the review depends heavily on the reviewer's current state of mind, time pressure, and experience level.
Pull Request Reviews
In the Git world, Pull Requests (or Merge Requests) have become the standard workflow. The developer creates a branch, makes changes, and submits a PR for review. Only after approval is the code merged into the main branch. This system provides a structured gate function: no unreviewed code reaches production. Platforms like GitHub and GitLab offer extensive tooling for this – inline comments, status checks, automatic reviewer assignment.
Pair Programming
In pair programming, two developers work on code together. The "driver" writes while the "navigator" thinks along, questions decisions, and catches errors in real time. This method often produces high-quality code because every line is implicitly reviewed by two people. The downside is the high cost: two developers working on one task. Additionally, pair programming is difficult to implement with distributed teams or asynchronous work arrangements.
All these approaches share a fundamental problem: they do not measure quality quantitatively. A review ends with "approved" or "changes requested" – but there is no number, no score, no tracking over time. You cannot say: "Our average commit quality increased by 12% in Q3."
Metrics That Matter
To make commit quality measurable, we need concrete, quantifiable metrics. Here are the most important ones.
Diff Size: The number of changed lines per commit is one of the most reliable indicators of commit quality. Small, focused commits (under 400 lines) are easier to review, simpler to revert, and generate fewer merge conflicts. Large commits (1000+ lines) often indicate a lack of planning – the developer has mixed too many tasks into a single commit. The probability that a reviewer overlooks a bug in a 2000-line diff is dramatically higher than in a 200-line diff.
Test Coverage Changes: A good commit adds not only new code but also the corresponding tests. The critical question is not "What is the overall coverage?" but "Did this commit improve, worsen, or maintain coverage?" Commits that introduce new code without tests lower the relative coverage and increase regression risk.
Cyclomatic Complexity: This metric measures the number of independent paths through a function. A function with a single if-statement has a complexity of 2 (two paths). Each additional condition, loop, or switch-case increases the complexity. Commits that push the cyclomatic complexity of functions above 10 signal that the function should be split. High complexity correlates directly with defect frequency.
Documentation Ratio: The ratio of comments and documentation to code reveals much about maintainability. This is not about trivial line comments ("increment counter") but about meaningful explanations of why a decision was made, what assumptions apply, and which edge cases were considered. A commit without any documentation in a complex area is a warning sign.
The SVN Problem: No Built-In Pull Request Workflow
While Git-based platforms like GitHub, GitLab, and Bitbucket offer extensive review tooling, SVN teams face a fundamental challenge: SVN has no native pull request mechanism.
In SVN, developers commit directly to the trunk or a branch. There is no intermediate review step, no "request for merge," no automatic reviewer assignment. The commit is immediately part of the repository. This model originates from an era when teams were smaller and trust was the primary quality assurance mechanism.
In modern teams, especially in regulated industries (medical technology, automotive, financial services), this model is problematic. Organizations that use SVN for historical reasons – existing infrastructure, compliance requirements, large binary files – often lack tools for systematic pre-commit reviews.
Some teams build workarounds: pre-commit hooks that enforce static analysis, or manual review processes via email or ticket systems. But these solutions are fragmented, difficult to maintain, and provide no trend data over time. This is precisely where integrating AI-powered reviews directly into the SVN client opens up entirely new possibilities.
How AI Can Evaluate Commits Objectively
AI-based code reviews solve several fundamental problems of traditional approaches simultaneously. An AI model evaluates every commit according to the same criteria – regardless of mood, personal preferences, or time pressure. This consistency is the greatest advantage over human reviews.
An AI review can analyze a commit's diff and evaluate it across categories such as:
- Code Quality – Is the code cleanly structured? Does it follow established patterns? Is there unnecessary complexity?
- Error Handling – Are error conditions addressed? Are try/catch blocks present where needed? Are edge cases handled?
- Performance – Are there inefficient algorithms, unnecessary computations, or potential memory leaks?
- Documentation – Are comments present and meaningful? Is the commit message descriptive?
The decisive difference: each category receives a numerical score (e.g., 1–10). This transforms quality from a subjective assessment into a measurable value. You can track these scores over time, compute averages, identify trends, and quantify improvements.
It is important to understand that AI reviews do not replace human reviews but complement them. The AI functions as a consistent first check – it catches obvious issues before a human reviewer invests their valuable time. This allows human reviewers to focus on the truly important aspects: architectural decisions, business logic, and strategic implications.
MaiPed's Approach: Category Scores and Trend Tracking
MaiPed integrates AI-powered code reviews directly into the SVN commit workflow. Before a commit is executed, the AI analyzes the changes and evaluates them across multiple categories with scores from 1 to 10.
Beyond individual reviews, MaiPed offers batch reviews, where multiple changed files are analyzed in a single pass. This is particularly useful when you have completed a larger feature branch and want a comprehensive overview of the quality of all changes before committing.
All review results are stored in MaiPed's local SQLite database and visualized in the Statistics view as interactive charts. There you can see at a glance how review scores develop over weeks and months, which categories are improving, and where regression is occurring. This data gives the entire team a common foundation for quality discussions – based on facts rather than gut feeling.
An additional advantage: AI providers are freely selectable. Teams can use OpenAI, Anthropic, or Mistral – or for maximum privacy, local models like Ollama and LM Studio. In that case, not a single byte leaves the machine.
Identifying Patterns with Review Scores
The greatest value of numerical review scores lies not in individual results but in the patterns that emerge over time. When you track scores across weeks and months, trends become visible that remain hidden in individual reviews.
Detecting Declining Quality: When average code quality scores fall continuously over three weeks, that is a clear signal. Perhaps a deadline is approaching and the team is sacrificing quality for speed. Perhaps a new team member has not yet internalized the conventions. Without data, this problem would only become visible later through bugs or customer tickets.
Identifying Specific Problem Areas: When error handling scores are consistently low (e.g., 5–6) while code quality and performance sit at 8–9, the team knows exactly where to focus. You can organize targeted workshops, supplement coding guidelines, or provide error handling templates.
Quantifying Improvements: After a team workshop on documentation, documentation scores should rise in the following weeks. If they do not, the workshop was not effective enough. Without measurable data, this insight would be purely speculative.
Individual Development: Commits-per-author statistics combined with average review scores show the development of individual team members. A junior developer whose scores steadily rise over months is making visible progress. This data can serve as an objective basis in performance conversations – positive and constructive.
Building a Quality Culture
The most powerful tool for commit quality is not technology but culture. Pre-commit reviews – whether from an AI or a colleague – must be understood as a safety net, not as an instrument of surveillance or blame.
When a developer sees a commit with low scores, the first reaction should not be shame but curiosity: What can I improve? What did I overlook? The score is feedback, not judgment. Teams that have internalized this attitude demonstrate measurably higher commit quality and simultaneously higher employee satisfaction.
How scores are communicated is critical. They should never be presented in public rankings or leaderboards that could single out individuals. Instead, aggregated team metrics work well: "Our average error handling score increased from 6.8 to 7.9." This celebrates team success without putting pressure on individuals.
Pre-commit reviews work best as an optional, informational layer. The developer sees the scores before committing and can decide whether to make changes or proceed with the commit regardless. There is no automatic blocking. This voluntariness is psychologically critical: people accept feedback more readily when they retain control over their response.
Practical Tips for SVN Teams
For teams using SVN that want to improve their commit quality, here are concrete, immediately actionable recommendations:
- Small Commits: Limit each commit to a single logical change. "Implemented Feature X" and "Refactored Module Y" belong in separate commits, even if they were created simultaneously.
- Commit Messages with Context: Write not just what changed but why. "Fixed bug in parser" becomes "Fixed null pointer in XML parser when processing empty attributes (Ticket #4521)."
- Enable Pre-Commit Reviews: Use a tool like MaiPed that offers AI reviews directly before committing. The additional 10–15 seconds of wait time saves hours of later debugging.
- Track Category Scores: Record scores over time and review trends monthly. Declining scores in any category are an early warning signal.
- Batch Reviews Before Major Releases: Before a release, run all changed files through a batch review. This catches problems that were not visible in individual commits.
- Team Retrospectives with Data: Bring review score trends into sprint retrospectives. Discuss patterns together and derive concrete action items.
- Documentation as Habit: Create a team checklist: every commit should contain at least one comment line per new function and a descriptive commit message.
- Local AI for Privacy: In regulated industries or with sensitive code: use local models (Ollama, LM Studio) for reviews. The code never leaves the machine.
Make Commit Quality Measurable
MaiPed brings AI-powered code reviews with category scores, batch reviews, and trend tracking directly into your SVN workflow – native for macOS.